

Upload 5 files
Browse files- README.md +474 -429
- media/xlam-bfcl.png +0 -0
- media/xlam-toolbench.png +0 -0
- media/xlam-unified_toolquery.png +0 -0
- media/xlam-webshop_toolquery.png +0 -0
README.md
CHANGED
|
@@ -1,429 +1,474 @@
|
|
| 1 |
-
---
|
| 2 |
-
extra_gated_heading: >-
|
| 3 |
-
Acknowledge to follow corresponding license to access the
|
| 4 |
-
repository
|
| 5 |
-
extra_gated_button_content: Agree and access repository
|
| 6 |
-
extra_gated_fields:
|
| 7 |
-
First Name: text
|
| 8 |
-
Last Name: text
|
| 9 |
-
Country: country
|
| 10 |
-
Affiliation: text
|
| 11 |
-
license: cc-by-nc-4.0
|
| 12 |
-
datasets:
|
| 13 |
-
- Salesforce/xlam-function-calling-60k
|
| 14 |
-
language:
|
| 15 |
-
- en
|
| 16 |
-
pipeline_tag: text-generation
|
| 17 |
-
tags:
|
| 18 |
-
- function-calling
|
| 19 |
-
- LLM Agent
|
| 20 |
-
- tool-use
|
| 21 |
-
- mistral
|
| 22 |
-
- pytorch
|
| 23 |
-
---
|
| 24 |
-
|
| 25 |
-
<p align="center">
|
| 26 |
-
<img width="500px" alt="xLAM" src="https://huggingface.co/datasets/jianguozhang/logos/resolve/main/xlam-no-background.png">
|
| 27 |
-
</p>
|
| 28 |
-
<p align="center">
|
| 29 |
-
<a href="">[Homepage]</a> |
|
| 30 |
-
<a href="">[Paper]</a> |
|
| 31 |
-
<a href="https://github.com/SalesforceAIResearch/xLAM">[Github]</a>
|
| 32 |
-
</
|
| 33 |
-
<
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
- [
|
| 43 |
-
- [
|
| 44 |
-
|
| 45 |
-
- [
|
| 46 |
-
- [
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
|
|
| 55 |
-
|
| 56 |
-
| xLAM-
|
| 57 |
-
| xLAM-
|
| 58 |
-
| xLAM-
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
For more details
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
-
|
| 80 |
-
-
|
| 81 |
-
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
|
| 85 |
-
|
| 86 |
-
|
| 87 |
-
|
| 88 |
-
|
| 89 |
-
```
|
| 90 |
-
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
|
| 96 |
-
|
| 97 |
-
|
| 98 |
-
|
| 99 |
-
|
| 100 |
-
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
|
| 117 |
-
|
| 118 |
-
```
|
| 119 |
-
"""
|
| 120 |
-
|
| 121 |
-
|
| 122 |
-
|
| 123 |
-
|
| 124 |
-
|
| 125 |
-
|
| 126 |
-
|
| 127 |
-
"
|
| 128 |
-
|
| 129 |
-
|
| 130 |
-
|
| 131 |
-
|
| 132 |
-
|
| 133 |
-
|
| 134 |
-
|
| 135 |
-
|
| 136 |
-
|
| 137 |
-
"
|
| 138 |
-
|
| 139 |
-
|
| 140 |
-
|
| 141 |
-
|
| 142 |
-
|
| 143 |
-
|
| 144 |
-
|
| 145 |
-
|
| 146 |
-
|
| 147 |
-
"
|
| 148 |
-
|
| 149 |
-
|
| 150 |
-
|
| 151 |
-
|
| 152 |
-
|
| 153 |
-
|
| 154 |
-
|
| 155 |
-
|
| 156 |
-
|
| 157 |
-
|
| 158 |
-
|
| 159 |
-
|
| 160 |
-
|
| 161 |
-
|
| 162 |
-
|
| 163 |
-
|
| 164 |
-
|
| 165 |
-
|
| 166 |
-
|
| 167 |
-
|
| 168 |
-
"
|
| 169 |
-
|
| 170 |
-
|
| 171 |
-
|
| 172 |
-
|
| 173 |
-
return tools
|
| 174 |
-
|
| 175 |
-
|
| 176 |
-
|
| 177 |
-
|
| 178 |
-
|
| 179 |
-
|
| 180 |
-
|
| 181 |
-
"
|
| 182 |
-
"
|
| 183 |
-
"
|
| 184 |
-
|
| 185 |
-
|
| 186 |
-
|
| 187 |
-
|
| 188 |
-
|
| 189 |
-
|
| 190 |
-
|
| 191 |
-
|
| 192 |
-
|
| 193 |
-
|
| 194 |
-
prompt
|
| 195 |
-
prompt += f"[BEGIN OF
|
| 196 |
-
|
| 197 |
-
|
| 198 |
-
|
| 199 |
-
|
| 200 |
-
|
| 201 |
-
|
| 202 |
-
|
| 203 |
-
|
| 204 |
-
|
| 205 |
-
|
| 206 |
-
|
| 207 |
-
|
| 208 |
-
|
| 209 |
-
|
| 210 |
-
|
| 211 |
-
|
| 212 |
-
|
| 213 |
-
|
| 214 |
-
|
| 215 |
-
|
| 216 |
-
|
| 217 |
-
|
| 218 |
-
|
| 219 |
-
|
| 220 |
-
|
| 221 |
-
```
|
| 222 |
-
|
| 223 |
-
|
| 224 |
-
|
| 225 |
-
|
| 226 |
-
|
| 227 |
-
|
| 228 |
-
|
| 229 |
-
|
| 230 |
-
|
| 231 |
-
"""
|
| 232 |
-
|
| 233 |
-
|
| 234 |
-
|
| 235 |
-
|
| 236 |
-
|
| 237 |
-
|
| 238 |
-
|
| 239 |
-
|
| 240 |
-
|
| 241 |
-
|
| 242 |
-
|
| 243 |
-
|
| 244 |
-
|
| 245 |
-
|
| 246 |
-
"""
|
| 247 |
-
|
| 248 |
-
|
| 249 |
-
|
| 250 |
-
|
| 251 |
-
"
|
| 252 |
-
"
|
| 253 |
-
"
|
| 254 |
-
"
|
| 255 |
-
|
| 256 |
-
|
| 257 |
-
|
| 258 |
-
|
| 259 |
-
|
| 260 |
-
|
| 261 |
-
|
| 262 |
-
"""
|
| 263 |
-
|
| 264 |
-
|
| 265 |
-
|
| 266 |
-
|
| 267 |
-
|
| 268 |
-
|
| 269 |
-
#
|
| 270 |
-
|
| 271 |
-
#
|
| 272 |
-
|
| 273 |
-
|
| 274 |
-
|
| 275 |
-
|
| 276 |
-
|
| 277 |
-
|
| 278 |
-
|
| 279 |
-
|
| 280 |
-
|
| 281 |
-
|
| 282 |
-
|
| 283 |
-
|
| 284 |
-
|
| 285 |
-
|
| 286 |
-
|
| 287 |
-
|
| 288 |
-
|
| 289 |
-
|
| 290 |
-
|
| 291 |
-
|
| 292 |
-
|
| 293 |
-
|
| 294 |
-
|
| 295 |
-
|
| 296 |
-
```
|
| 297 |
-
|
| 298 |
-
|
| 299 |
-
|
| 300 |
-
|
| 301 |
-
|
| 302 |
-
|
| 303 |
-
|
| 304 |
-
|
| 305 |
-
|
| 306 |
-
[
|
| 307 |
-
|
| 308 |
-
[
|
| 309 |
-
|
| 310 |
-
|
| 311 |
-
|
| 312 |
-
|
| 313 |
-
"
|
| 314 |
-
|
| 315 |
-
|
| 316 |
-
|
| 317 |
-
"
|
| 318 |
-
"
|
| 319 |
-
|
| 320 |
-
|
| 321 |
-
|
| 322 |
-
|
| 323 |
-
"
|
| 324 |
-
"
|
| 325 |
-
|
| 326 |
-
|
| 327 |
-
|
| 328 |
-
|
| 329 |
-
|
| 330 |
-
|
| 331 |
-
"
|
| 332 |
-
|
| 333 |
-
|
| 334 |
-
|
| 335 |
-
"
|
| 336 |
-
"
|
| 337 |
-
|
| 338 |
-
|
| 339 |
-
|
| 340 |
-
|
| 341 |
-
|
| 342 |
-
|
| 343 |
-
"
|
| 344 |
-
|
| 345 |
-
|
| 346 |
-
|
| 347 |
-
"
|
| 348 |
-
"
|
| 349 |
-
|
| 350 |
-
|
| 351 |
-
|
| 352 |
-
|
| 353 |
-
"
|
| 354 |
-
"
|
| 355 |
-
|
| 356 |
-
|
| 357 |
-
|
| 358 |
-
|
| 359 |
-
|
| 360 |
-
|
| 361 |
-
[
|
| 362 |
-
|
| 363 |
-
|
| 364 |
-
|
| 365 |
-
|
| 366 |
-
[
|
| 367 |
-
|
| 368 |
-
[
|
| 369 |
-
|
| 370 |
-
[
|
| 371 |
-
|
| 372 |
-
|
| 373 |
-
|
| 374 |
-
|
| 375 |
-
"
|
| 376 |
-
"
|
| 377 |
-
"
|
| 378 |
-
|
| 379 |
-
|
| 380 |
-
|
| 381 |
-
|
| 382 |
-
|
| 383 |
-
|
| 384 |
-
|
| 385 |
-
|
| 386 |
-
|
| 387 |
-
|
| 388 |
-
|
| 389 |
-
|
| 390 |
-
|
| 391 |
-
|
| 392 |
-
|
| 393 |
-
|
| 394 |
-
|
| 395 |
-
"
|
| 396 |
-
|
| 397 |
-
|
| 398 |
-
|
| 399 |
-
|
| 400 |
-
"
|
| 401 |
-
|
| 402 |
-
|
| 403 |
-
|
| 404 |
-
|
| 405 |
-
|
| 406 |
-
|
| 407 |
-
"
|
| 408 |
-
"
|
| 409 |
-
"
|
| 410 |
-
|
| 411 |
-
|
| 412 |
-
|
| 413 |
-
|
| 414 |
-
|
| 415 |
-
|
| 416 |
-
|
| 417 |
-
|
| 418 |
-
|
| 419 |
-
````
|
| 420 |
-
|
| 421 |
-
|
| 422 |
-
|
| 423 |
-
|
| 424 |
-
|
| 425 |
-
|
| 426 |
-
|
| 427 |
-
|
| 428 |
-
|
| 429 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
extra_gated_heading: >-
|
| 3 |
+
Acknowledge to follow corresponding license to access the
|
| 4 |
+
repository
|
| 5 |
+
extra_gated_button_content: Agree and access repository
|
| 6 |
+
extra_gated_fields:
|
| 7 |
+
First Name: text
|
| 8 |
+
Last Name: text
|
| 9 |
+
Country: country
|
| 10 |
+
Affiliation: text
|
| 11 |
+
license: cc-by-nc-4.0
|
| 12 |
+
datasets:
|
| 13 |
+
- Salesforce/xlam-function-calling-60k
|
| 14 |
+
language:
|
| 15 |
+
- en
|
| 16 |
+
pipeline_tag: text-generation
|
| 17 |
+
tags:
|
| 18 |
+
- function-calling
|
| 19 |
+
- LLM Agent
|
| 20 |
+
- tool-use
|
| 21 |
+
- mistral
|
| 22 |
+
- pytorch
|
| 23 |
+
---
|
| 24 |
+
|
| 25 |
+
<p align="center">
|
| 26 |
+
<img width="500px" alt="xLAM" src="https://huggingface.co/datasets/jianguozhang/logos/resolve/main/xlam-no-background.png">
|
| 27 |
+
</p>
|
| 28 |
+
<p align="center">
|
| 29 |
+
<a href="https://www.salesforceairesearch.com/projects/xlam-large-action-models">[Homepage]</a> |
|
| 30 |
+
<a href="https://arxiv.org/abs/2409.03215">[Paper]</a> |
|
| 31 |
+
<a href="https://github.com/SalesforceAIResearch/xLAM">[Github]</a> |
|
| 32 |
+
<a href="https://blog.salesforceairesearch.com/large-action-model-ai-agent/">[Blog]</a> |
|
| 33 |
+
<a href="https://huggingface.co/spaces/Tonic/Salesforce-Xlam-7b-r">[Community Demo]</a>
|
| 34 |
+
</p>
|
| 35 |
+
<hr>
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
Welcome to the xLAM model family! [Large Action Models (LAMs)](https://blog.salesforceairesearch.com/large-action-models/) are advanced large language models designed to enhance decision-making and translate user intentions into executable actions that interact with the world. LAMs autonomously plan and execute tasks to achieve specific goals, serving as the brains of AI agents. They have the potential to automate workflow processes across various domains, making them invaluable for a wide range of applications.
|
| 39 |
+
**The model release is exclusively for research purposes. A new and enhanced version of xLAM will soon be available exclusively to customers on our Platform.**
|
| 40 |
+
|
| 41 |
+
## Table of Contents
|
| 42 |
+
- [Model Series](#model-series)
|
| 43 |
+
- [Repository Overview](#repository-overview)
|
| 44 |
+
- [Benchmark Results](#benchmark-results)
|
| 45 |
+
- [Usage](#usage)
|
| 46 |
+
- [Basic Usage with Huggingface](#basic-usage-with-huggingface)
|
| 47 |
+
- [License](#license)
|
| 48 |
+
- [Citation](#citation)
|
| 49 |
+
|
| 50 |
+
## Model Series
|
| 51 |
+
|
| 52 |
+
We provide a series of xLAMs in different sizes to cater to various applications, including those optimized for function-calling and general agent applications:
|
| 53 |
+
|
| 54 |
+
| Model | # Total Params | Context Length | Download Model | Download GGUF files |
|
| 55 |
+
|------------------------|----------------|----------------|----------------|----------|
|
| 56 |
+
| xLAM-1b-fc-r | 1.35B | 16k | [🤗 Link](https://huggingface.co/Salesforce/xLAM-1b-fc-r) | [🤗 Link](https://huggingface.co/Salesforce/xLAM-1b-fc-r-gguf) |
|
| 57 |
+
| xLAM-7b-fc-r | 6.91B | 4k | [🤗 Link](https://huggingface.co/Salesforce/xLAM-7b-fc-r) | [🤗 Link](https://huggingface.co/Salesforce/xLAM-7b-fc-r-gguf) |
|
| 58 |
+
| xLAM-7b-r | 7.24B | 32k | [🤗 Link](https://huggingface.co/Salesforce/xLAM-7b-r) | -- |
|
| 59 |
+
| xLAM-8x7b-r | 46.7B | 32k | [🤗 Link](https://huggingface.co/Salesforce/xLAM-8x7b-r) | -- |
|
| 60 |
+
| xLAM-8x22b-r | 141B | 64k | [🤗 Link](https://huggingface.co/Salesforce/xLAM-8x22b-r) | -- |
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
For our Function-calling series (more details are included at [here](https://huggingface.co/Salesforce/xLAM-7b-fc-r)), we also provide their quantized [GGUF](https://huggingface.co/docs/hub/en/gguf) files for efficient deployment and execution. GGUF is a file format designed to efficiently store and load large language models, making GGUF ideal for running AI models on local devices with limited resources, enabling offline functionality and enhanced privacy.
|
| 68 |
+
|
| 69 |
+
For more details, check our [GitHub](https://github.com/SalesforceAIResearch/xLAM) and [paper]().
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
## Repository Overview
|
| 73 |
+
|
| 74 |
+
This repository is about the general tool use series. For more specialized function calling models, please take a look into our `fc` series [here](https://huggingface.co/Salesforce/xLAM-7b-fc-r).
|
| 75 |
+
|
| 76 |
+
The instructions will guide you through the setup, usage, and integration of our model series with HuggingFace.
|
| 77 |
+
### Framework Versions
|
| 78 |
+
|
| 79 |
+
- Transformers 4.41.0
|
| 80 |
+
- Pytorch 2.3.0+cu121
|
| 81 |
+
- Datasets 2.19.1
|
| 82 |
+
- Tokenizers 0.19.1
|
| 83 |
+
|
| 84 |
+
## Usage
|
| 85 |
+
|
| 86 |
+
### Basic Usage with Huggingface
|
| 87 |
+
|
| 88 |
+
To use the model from Huggingface, please first install the `transformers` library:
|
| 89 |
+
```bash
|
| 90 |
+
pip install transformers>=4.41.0
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
Please note that, our model works best with our provided prompt format.
|
| 94 |
+
It allows us to extract JSON output that is similar to the [function-calling mode of ChatGPT](https://platform.openai.com/docs/guides/function-calling).
|
| 95 |
+
|
| 96 |
+
We use the following example to illustrate how to use our model for 1) single-turn use case, and 2) multi-turn use case
|
| 97 |
+
|
| 98 |
+
#### 1. Single-turn use case
|
| 99 |
+
|
| 100 |
+
````python
|
| 101 |
+
import json
|
| 102 |
+
import torch
|
| 103 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 104 |
+
|
| 105 |
+
torch.random.manual_seed(0)
|
| 106 |
+
|
| 107 |
+
model_name = "Salesforce/xLAM-7b-r"
|
| 108 |
+
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype="auto", trust_remote_code=True)
|
| 109 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 110 |
+
|
| 111 |
+
# Please use our provided instruction prompt for best performance
|
| 112 |
+
task_instruction = """
|
| 113 |
+
Based on the previous context and API request history, generate an API request or a response as an AI assistant.""".strip()
|
| 114 |
+
|
| 115 |
+
format_instruction = """
|
| 116 |
+
The output should be of the JSON format, which specifies a list of generated function calls. The example format is as follows, please make sure the parameter type is correct. If no function call is needed, please make
|
| 117 |
+
tool_calls an empty list "[]".
|
| 118 |
+
```
|
| 119 |
+
{"thought": "the thought process, or an empty string", "tool_calls": [{"name": "api_name1", "arguments": {"argument1": "value1", "argument2": "value2"}}]}
|
| 120 |
+
```
|
| 121 |
+
""".strip()
|
| 122 |
+
|
| 123 |
+
# Define the input query and available tools
|
| 124 |
+
query = "What's the weather like in New York in fahrenheit?"
|
| 125 |
+
|
| 126 |
+
get_weather_api = {
|
| 127 |
+
"name": "get_weather",
|
| 128 |
+
"description": "Get the current weather for a location",
|
| 129 |
+
"parameters": {
|
| 130 |
+
"type": "object",
|
| 131 |
+
"properties": {
|
| 132 |
+
"location": {
|
| 133 |
+
"type": "string",
|
| 134 |
+
"description": "The city and state, e.g. San Francisco, New York"
|
| 135 |
+
},
|
| 136 |
+
"unit": {
|
| 137 |
+
"type": "string",
|
| 138 |
+
"enum": ["celsius", "fahrenheit"],
|
| 139 |
+
"description": "The unit of temperature to return"
|
| 140 |
+
}
|
| 141 |
+
},
|
| 142 |
+
"required": ["location"]
|
| 143 |
+
}
|
| 144 |
+
}
|
| 145 |
+
|
| 146 |
+
search_api = {
|
| 147 |
+
"name": "search",
|
| 148 |
+
"description": "Search for information on the internet",
|
| 149 |
+
"parameters": {
|
| 150 |
+
"type": "object",
|
| 151 |
+
"properties": {
|
| 152 |
+
"query": {
|
| 153 |
+
"type": "string",
|
| 154 |
+
"description": "The search query, e.g. 'latest news on AI'"
|
| 155 |
+
}
|
| 156 |
+
},
|
| 157 |
+
"required": ["query"]
|
| 158 |
+
}
|
| 159 |
+
}
|
| 160 |
+
|
| 161 |
+
openai_format_tools = [get_weather_api, search_api]
|
| 162 |
+
|
| 163 |
+
# Helper function to convert openai format tools to our more concise xLAM format
|
| 164 |
+
def convert_to_xlam_tool(tools):
|
| 165 |
+
''''''
|
| 166 |
+
if isinstance(tools, dict):
|
| 167 |
+
return {
|
| 168 |
+
"name": tools["name"],
|
| 169 |
+
"description": tools["description"],
|
| 170 |
+
"parameters": {k: v for k, v in tools["parameters"].get("properties", {}).items()}
|
| 171 |
+
}
|
| 172 |
+
elif isinstance(tools, list):
|
| 173 |
+
return [convert_to_xlam_tool(tool) for tool in tools]
|
| 174 |
+
else:
|
| 175 |
+
return tools
|
| 176 |
+
|
| 177 |
+
def build_conversation_history_prompt(conversation_history: str):
|
| 178 |
+
parsed_history = []
|
| 179 |
+
for step_data in conversation_history:
|
| 180 |
+
parsed_history.append({
|
| 181 |
+
"step_id": step_data["step_id"],
|
| 182 |
+
"thought": step_data["thought"],
|
| 183 |
+
"tool_calls": step_data["tool_calls"],
|
| 184 |
+
"next_observation": step_data["next_observation"],
|
| 185 |
+
"user_input": step_data['user_input']
|
| 186 |
+
})
|
| 187 |
+
|
| 188 |
+
history_string = json.dumps(parsed_history)
|
| 189 |
+
return f"\n[BEGIN OF HISTORY STEPS]\n{history_string}\n[END OF HISTORY STEPS]\n"
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
# Helper function to build the input prompt for our model
|
| 193 |
+
def build_prompt(task_instruction: str, format_instruction: str, tools: list, query: str, conversation_history: list):
|
| 194 |
+
prompt = f"[BEGIN OF TASK INSTRUCTION]\n{task_instruction}\n[END OF TASK INSTRUCTION]\n\n"
|
| 195 |
+
prompt += f"[BEGIN OF AVAILABLE TOOLS]\n{json.dumps(xlam_format_tools)}\n[END OF AVAILABLE TOOLS]\n\n"
|
| 196 |
+
prompt += f"[BEGIN OF FORMAT INSTRUCTION]\n{format_instruction}\n[END OF FORMAT INSTRUCTION]\n\n"
|
| 197 |
+
prompt += f"[BEGIN OF QUERY]\n{query}\n[END OF QUERY]\n\n"
|
| 198 |
+
|
| 199 |
+
if len(conversation_history) > 0: prompt += build_conversation_history_prompt(conversation_history)
|
| 200 |
+
return prompt
|
| 201 |
+
|
| 202 |
+
# Build the input and start the inference
|
| 203 |
+
xlam_format_tools = convert_to_xlam_tool(openai_format_tools)
|
| 204 |
+
|
| 205 |
+
conversation_history = []
|
| 206 |
+
content = build_prompt(task_instruction, format_instruction, xlam_format_tools, query, conversation_history)
|
| 207 |
+
|
| 208 |
+
messages=[
|
| 209 |
+
{ 'role': 'user', 'content': content}
|
| 210 |
+
]
|
| 211 |
+
|
| 212 |
+
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
|
| 213 |
+
|
| 214 |
+
# tokenizer.eos_token_id is the id of <|EOT|> token
|
| 215 |
+
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
|
| 216 |
+
agent_action = tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True)
|
| 217 |
+
````
|
| 218 |
+
|
| 219 |
+
Then you should be able to see the following output string in JSON format:
|
| 220 |
+
|
| 221 |
+
```shell
|
| 222 |
+
{"thought": "I need to get the current weather for New York in fahrenheit.", "tool_calls": [{"name": "get_weather", "arguments": {"location": "New York", "unit": "fahrenheit"}}]}
|
| 223 |
+
```
|
| 224 |
+
|
| 225 |
+
#### 2. Multi-turn use case
|
| 226 |
+
|
| 227 |
+
We also support multi-turn interaction with our model series. Here is the example of next round of interaction from the above example:
|
| 228 |
+
|
| 229 |
+
````python
|
| 230 |
+
def parse_agent_action(agent_action: str):
|
| 231 |
+
"""
|
| 232 |
+
Given an agent's action, parse it to add to conversation history
|
| 233 |
+
"""
|
| 234 |
+
try: parsed_agent_action_json = json.loads(agent_action)
|
| 235 |
+
except: return "", []
|
| 236 |
+
|
| 237 |
+
if "thought" not in parsed_agent_action_json.keys(): thought = ""
|
| 238 |
+
else: thought = parsed_agent_action_json["thought"]
|
| 239 |
+
|
| 240 |
+
if "tool_calls" not in parsed_agent_action_json.keys(): tool_calls = []
|
| 241 |
+
else: tool_calls = parsed_agent_action_json["tool_calls"]
|
| 242 |
+
|
| 243 |
+
return thought, tool_calls
|
| 244 |
+
|
| 245 |
+
def update_conversation_history(conversation_history: list, agent_action: str, environment_response: str, user_input: str):
|
| 246 |
+
"""
|
| 247 |
+
Update the conversation history list based on the new agent_action, environment_response, and/or user_input
|
| 248 |
+
"""
|
| 249 |
+
thought, tool_calls = parse_agent_action(agent_action)
|
| 250 |
+
new_step_data = {
|
| 251 |
+
"step_id": len(conversation_history) + 1,
|
| 252 |
+
"thought": thought,
|
| 253 |
+
"tool_calls": tool_calls,
|
| 254 |
+
"step_id": len(conversation_history),
|
| 255 |
+
"next_observation": environment_response,
|
| 256 |
+
"user_input": user_input,
|
| 257 |
+
}
|
| 258 |
+
|
| 259 |
+
conversation_history.append(new_step_data)
|
| 260 |
+
|
| 261 |
+
def get_environment_response(agent_action: str):
|
| 262 |
+
"""
|
| 263 |
+
Get the environment response for the agent_action
|
| 264 |
+
"""
|
| 265 |
+
# TODO: add custom implementation here
|
| 266 |
+
error_message, response_message = "", ""
|
| 267 |
+
return {"error": error_message, "response": response_message}
|
| 268 |
+
|
| 269 |
+
# ------------- before here are the steps to get agent_response from the example above ----------
|
| 270 |
+
|
| 271 |
+
# 1. get the next state after agent's response:
|
| 272 |
+
# The next 2 lines are examples of getting environment response and user_input.
|
| 273 |
+
# It is depended on particular usage, we can have either one or both of those.
|
| 274 |
+
environment_response = get_environment_response(agent_action)
|
| 275 |
+
user_input = "Now, search on the Internet for cute puppies"
|
| 276 |
+
|
| 277 |
+
# 2. after we got environment_response and (or) user_input, we want to add to our conversation history
|
| 278 |
+
update_conversation_history(conversation_history, agent_action, environment_response, user_input)
|
| 279 |
+
|
| 280 |
+
# 3. we now can build the prompt
|
| 281 |
+
content = build_prompt(task_instruction, format_instruction, xlam_format_tools, query, conversation_history)
|
| 282 |
+
|
| 283 |
+
# 4. Now, we just retrieve the inputs for the LLM
|
| 284 |
+
messages=[
|
| 285 |
+
{ 'role': 'user', 'content': content}
|
| 286 |
+
]
|
| 287 |
+
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
|
| 288 |
+
|
| 289 |
+
# 5. Generate the outputs & decode
|
| 290 |
+
# tokenizer.eos_token_id is the id of <|EOT|> token
|
| 291 |
+
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
|
| 292 |
+
agent_action = tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True)
|
| 293 |
+
````
|
| 294 |
+
|
| 295 |
+
This would be the corresponding output:
|
| 296 |
+
```shell
|
| 297 |
+
{"thought": "I need to get the current weather for New York in fahrenheit.", "tool_calls": [{"name": "get_weather", "arguments": {"location": "New York", "unit": "fahrenheit"}}]}
|
| 298 |
+
```
|
| 299 |
+
|
| 300 |
+
We highly recommend to use our provided prompt format and helper functions to yield the best function-calling performance of our model.
|
| 301 |
+
|
| 302 |
+
#### Example multi-turn prompt and output
|
| 303 |
+
|
| 304 |
+
Prompt:
|
| 305 |
+
````json
|
| 306 |
+
[BEGIN OF TASK INSTRUCTION]
|
| 307 |
+
Based on the previous context and API request history, generate an API request or a response as an AI assistant.
|
| 308 |
+
[END OF TASK INSTRUCTION]
|
| 309 |
+
|
| 310 |
+
[BEGIN OF AVAILABLE TOOLS]
|
| 311 |
+
[
|
| 312 |
+
{
|
| 313 |
+
"name": "get_fire_info",
|
| 314 |
+
"description": "Query the latest wildfire information",
|
| 315 |
+
"parameters": {
|
| 316 |
+
"location": {
|
| 317 |
+
"type": "string",
|
| 318 |
+
"description": "Location of the wildfire, for example: 'California'",
|
| 319 |
+
"required": true,
|
| 320 |
+
"format": "free"
|
| 321 |
+
},
|
| 322 |
+
"radius": {
|
| 323 |
+
"type": "number",
|
| 324 |
+
"description": "The radius (in miles) around the location where the wildfire is occurring, for example: 10",
|
| 325 |
+
"required": false,
|
| 326 |
+
"format": "free"
|
| 327 |
+
}
|
| 328 |
+
}
|
| 329 |
+
},
|
| 330 |
+
{
|
| 331 |
+
"name": "get_hurricane_info",
|
| 332 |
+
"description": "Query the latest hurricane information",
|
| 333 |
+
"parameters": {
|
| 334 |
+
"name": {
|
| 335 |
+
"type": "string",
|
| 336 |
+
"description": "Name of the hurricane, for example: 'Irma'",
|
| 337 |
+
"required": true,
|
| 338 |
+
"format": "free"
|
| 339 |
+
}
|
| 340 |
+
}
|
| 341 |
+
},
|
| 342 |
+
{
|
| 343 |
+
"name": "get_earthquake_info",
|
| 344 |
+
"description": "Query the latest earthquake information",
|
| 345 |
+
"parameters": {
|
| 346 |
+
"magnitude": {
|
| 347 |
+
"type": "number",
|
| 348 |
+
"description": "The minimum magnitude of the earthquake that needs to be queried.",
|
| 349 |
+
"required": false,
|
| 350 |
+
"format": "free"
|
| 351 |
+
},
|
| 352 |
+
"location": {
|
| 353 |
+
"type": "string",
|
| 354 |
+
"description": "Location of the earthquake, for example: 'California'",
|
| 355 |
+
"required": false,
|
| 356 |
+
"format": "free"
|
| 357 |
+
}
|
| 358 |
+
}
|
| 359 |
+
}
|
| 360 |
+
]
|
| 361 |
+
[END OF AVAILABLE TOOLS]
|
| 362 |
+
|
| 363 |
+
[BEGIN OF FORMAT INSTRUCTION]
|
| 364 |
+
Your output should be in the JSON format, which specifies a list of function calls. The example format is as follows. Please make sure the parameter type is correct. If no function call is needed, please make tool_calls an empty list '[]'.
|
| 365 |
+
```{"thought": "the thought process, or an empty string", "tool_calls": [{"name": "api_name1", "arguments": {"argument1": "value1", "argument2": "value2"}}]}```
|
| 366 |
+
[END OF FORMAT INSTRUCTION]
|
| 367 |
+
|
| 368 |
+
[BEGIN OF QUERY]
|
| 369 |
+
User: Can you give me the latest information on the wildfires occurring in California?
|
| 370 |
+
[END OF QUERY]
|
| 371 |
+
|
| 372 |
+
[BEGIN OF HISTORY STEPS]
|
| 373 |
+
[
|
| 374 |
+
{
|
| 375 |
+
"thought": "Sure, what is the radius (in miles) around the location of the wildfire?",
|
| 376 |
+
"tool_calls": [],
|
| 377 |
+
"step_id": 1,
|
| 378 |
+
"next_observation": "",
|
| 379 |
+
"user_input": "User: Let me think... 50 miles."
|
| 380 |
+
},
|
| 381 |
+
{
|
| 382 |
+
"thought": "",
|
| 383 |
+
"tool_calls": [
|
| 384 |
+
{
|
| 385 |
+
"name": "get_fire_info",
|
| 386 |
+
"arguments": {
|
| 387 |
+
"location": "California",
|
| 388 |
+
"radius": 50
|
| 389 |
+
}
|
| 390 |
+
}
|
| 391 |
+
],
|
| 392 |
+
"step_id": 2,
|
| 393 |
+
"next_observation": [
|
| 394 |
+
{
|
| 395 |
+
"location": "Los Angeles",
|
| 396 |
+
"acres_burned": 1500,
|
| 397 |
+
"status": "contained"
|
| 398 |
+
},
|
| 399 |
+
{
|
| 400 |
+
"location": "San Diego",
|
| 401 |
+
"acres_burned": 12000,
|
| 402 |
+
"status": "active"
|
| 403 |
+
}
|
| 404 |
+
]
|
| 405 |
+
},
|
| 406 |
+
{
|
| 407 |
+
"thought": "Based on the latest information, there are wildfires in Los Angeles and San Diego. The wildfire in Los Angeles has burned 1,500 acres and is contained, while the wildfire in San Diego has burned 12,000 acres and is still active.",
|
| 408 |
+
"tool_calls": [],
|
| 409 |
+
"step_id": 3,
|
| 410 |
+
"next_observation": "",
|
| 411 |
+
"user_input": "User: Can you tell me about the latest earthquake?"
|
| 412 |
+
}
|
| 413 |
+
]
|
| 414 |
+
|
| 415 |
+
[END OF HISTORY STEPS]
|
| 416 |
+
````
|
| 417 |
+
|
| 418 |
+
Output:
|
| 419 |
+
````json
|
| 420 |
+
{"thought": "", "tool_calls": [{"name": "get_earthquake_info", "arguments": {"location": "California"}}]}
|
| 421 |
+
````
|
| 422 |
+
|
| 423 |
+
## Benchmark Results
|
| 424 |
+
Note: **Bold** and <u>Underline</u> results denote the best result and the second best result for Success Rate, respectively.
|
| 425 |
+
|
| 426 |
+
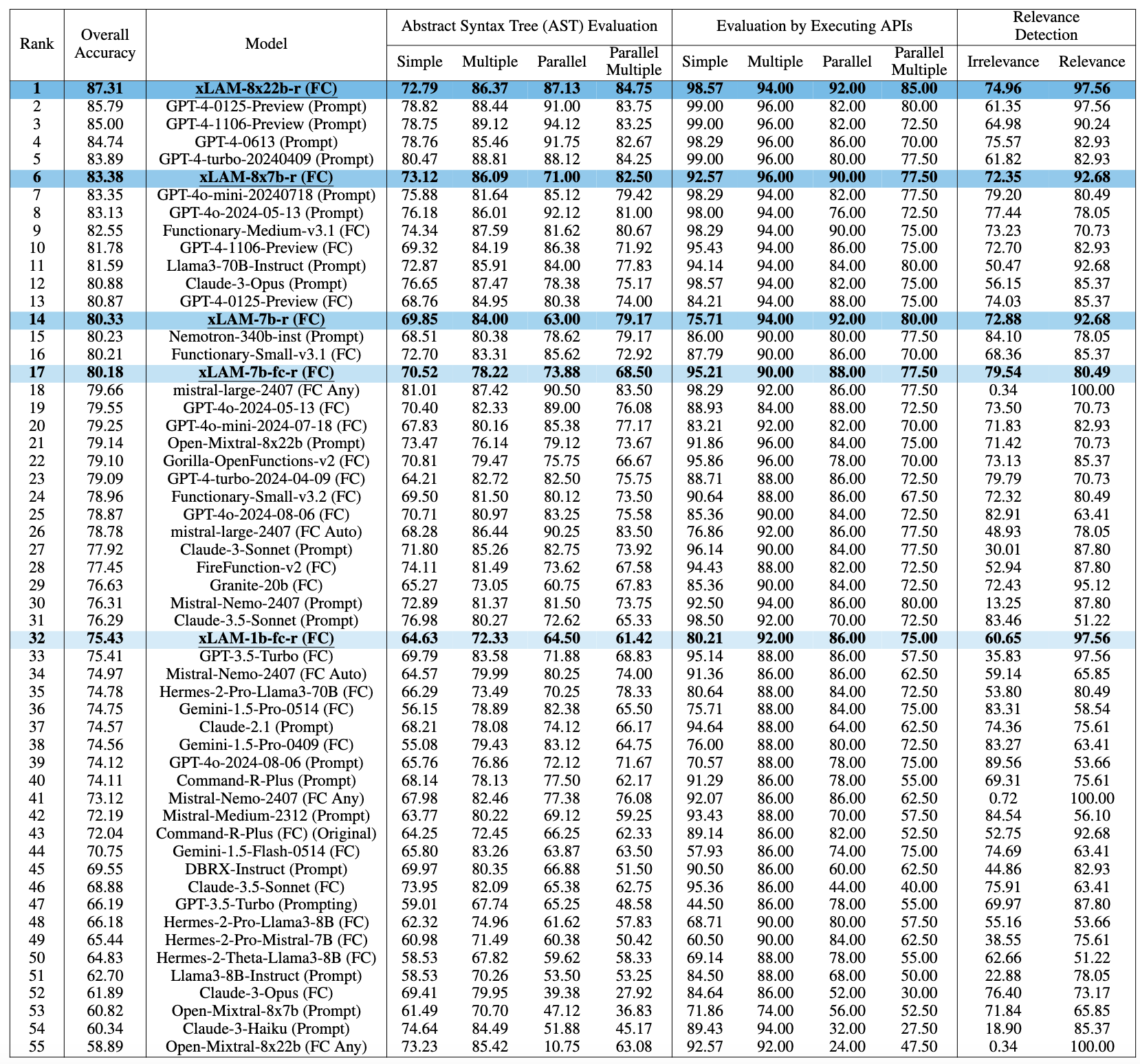
### Berkeley Function-Calling Leaderboard (BFCL)
|
| 427 |
+

|
| 428 |
+
*Table 1: Performance comparison on BFCL-v2 leaderboard (cutoff date 09/03/2024). The rank is based on the overall accuracy, which is a weighted average of different evaluation categories. "FC" stands for function-calling mode in contrast to using a customized "prompt" to extract the function calls.*
|
| 429 |
+
|
| 430 |
+
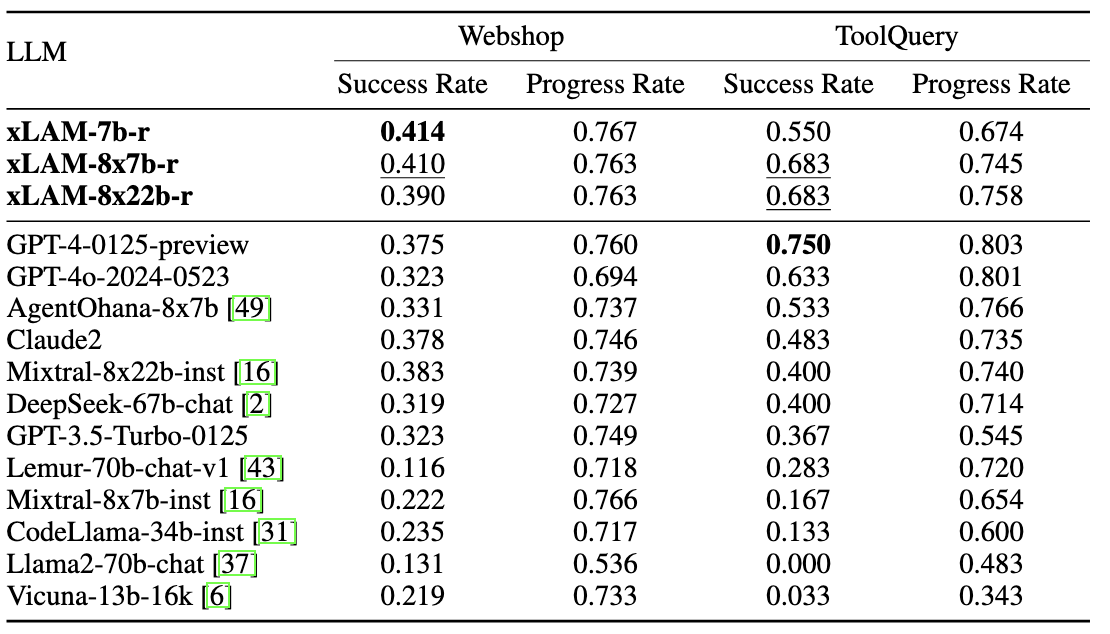
### Webshop and ToolQuery
|
| 431 |
+

|
| 432 |
+
*Table 2: Testing results on Webshop and ToolQuery. Bold and Underline results denote the best result and the second best result for Success Rate, respectively.*
|
| 433 |
+
|
| 434 |
+
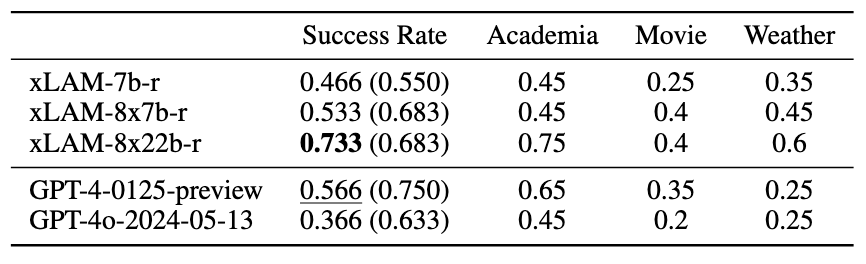
### Unified ToolQuery
|
| 435 |
+

|
| 436 |
+
*Table 3: Testing results on ToolQuery-Unified. Bold and Underline results denote the best result and the second best result for Success Rate, respectively. Values in brackets indicate corresponding performance on ToolQuery*
|
| 437 |
+
|
| 438 |
+
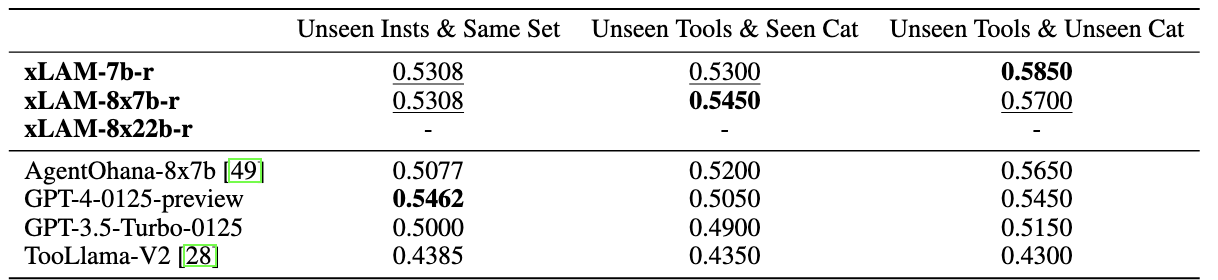
### ToolBench
|
| 439 |
+

|
| 440 |
+
*Table 4: Pass Rate on ToolBench on three distinct scenarios. Bold and Underline results denote the best result and the second best result for each setting, respectively. The results for xLAM-8x22b-r are unavailable due to the ToolBench server being down between 07/28/2024 and our evaluation cutoff date 09/03/2024.*
|
| 441 |
+
|
| 442 |
+
## License
|
| 443 |
+
The model is distributed under the CC-BY-NC-4.0 license.
|
| 444 |
+
|
| 445 |
+
## Citation
|
| 446 |
+
|
| 447 |
+
If you find this repo helpful, please consider to cite our papers:
|
| 448 |
+
|
| 449 |
+
```bibtex
|
| 450 |
+
@article{zhang2024xlam,
|
| 451 |
+
title={xLAM: A Family of Large Action Models to Empower AI Agent Systems},
|
| 452 |
+
author={Zhang, Jianguo and Lan, Tian and Zhu, Ming and Liu, Zuxin and Hoang, Thai and Kokane, Shirley and Yao, Weiran and Tan, Juntao and Prabhakar, Akshara and Chen, Haolin and others},
|
| 453 |
+
journal={arXiv preprint arXiv:2409.03215},
|
| 454 |
+
year={2024}
|
| 455 |
+
}
|
| 456 |
+
```
|
| 457 |
+
|
| 458 |
+
```bibtex
|
| 459 |
+
@article{liu2024apigen,
|
| 460 |
+
title={Apigen: Automated pipeline for generating verifiable and diverse function-calling datasets},
|
| 461 |
+
author={Liu, Zuxin and Hoang, Thai and Zhang, Jianguo and Zhu, Ming and Lan, Tian and Kokane, Shirley and Tan, Juntao and Yao, Weiran and Liu, Zhiwei and Feng, Yihao and others},
|
| 462 |
+
journal={arXiv preprint arXiv:2406.18518},
|
| 463 |
+
year={2024}
|
| 464 |
+
}
|
| 465 |
+
```
|
| 466 |
+
|
| 467 |
+
```bibtex
|
| 468 |
+
@article{zhang2024agentohana,
|
| 469 |
+
title={AgentOhana: Design Unified Data and Training Pipeline for Effective Agent Learning},
|
| 470 |
+
author={Zhang, Jianguo and Lan, Tian and Murthy, Rithesh and Liu, Zhiwei and Yao, Weiran and Tan, Juntao and Hoang, Thai and Yang, Liangwei and Feng, Yihao and Liu, Zuxin and others},
|
| 471 |
+
journal={arXiv preprint arXiv:2402.15506},
|
| 472 |
+
year={2024}
|
| 473 |
+
}
|
| 474 |
+
```
|
media/xlam-bfcl.png
ADDED
|
media/xlam-toolbench.png
ADDED
|
media/xlam-unified_toolquery.png
ADDED
|
media/xlam-webshop_toolquery.png
ADDED
|