
Du Chen
commited on
Commit
•
48fb4f3
1
Parent(s):
c82293b
update readme
Browse files- README.md +15 -9
- README_cn.md +21 -11
- assets/imgs/opencompass_en.png +0 -0
- assets/imgs/opencompass_zh.png +0 -0
README.md
CHANGED
|
@@ -17,7 +17,7 @@ pipeline_tag: text-generation
|
|
| 17 |
|
| 18 |
<div align="center">
|
| 19 |
<h1>
|
| 20 |
-
Orion-14B
|
| 21 |
</h1>
|
| 22 |
</div>
|
| 23 |
|
|
@@ -57,9 +57,16 @@ pipeline_tag: text-generation
|
|
| 57 |
- The fine-tuned models demonstrate strong adaptability, excelling in human-annotated blind tests.
|
| 58 |
- The long-chat version supports extremely long texts, extending up to 200K tokens.
|
| 59 |
- The quantized versions reduce model size by 70%, improve inference speed by 30%, with performance loss less than 1%.
|
| 60 |
-
<
|
| 61 |
-
|
| 62 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 63 |
|
| 64 |
- Orion-14B series models including:
|
| 65 |
- **Orion-14B-Base:** A multilingual large language foundational model with 14 billion parameters, pretrained on a diverse dataset of 2.5 trillion tokens.
|
|
@@ -105,7 +112,7 @@ Model release and download links are provided in the table below:
|
|
| 105 |
| Baichuan 2-13B | 68.9 | 67.2 | 70.8 | 78.1 | 74.1 | 66.3 |
|
| 106 |
| QWEN-14B | 93.0 | 90.3 | **80.2** | 79.8 | 71.4 | 66.3 |
|
| 107 |
| InternLM-20B | 86.4 | 83.3 | 78.1 | **80.3** | 71.8 | 68.3 |
|
| 108 |
-
| **Orion-14B-Base** | **93.
|
| 109 |
|
| 110 |
### 3.1.3. LLM evaluation results of OpenCompass testsets
|
| 111 |
| Model | Average | Examination | Language | Knowledge | Understanding | Reasoning |
|
|
@@ -115,7 +122,7 @@ Model release and download links are provided in the table below:
|
|
| 115 |
| Baichuan 2-13B | 49.4 | 51.8 | 47.5 | 48.9 | 58.1 | 44.2 |
|
| 116 |
| QWEN-14B | 62.4 | 71.3 | 52.67 | 56.1 | 68.8 | 60.1 |
|
| 117 |
| InternLM-20B | 59.4 | 62.5 | 55.0 | **60.1** | 67.3 | 54.9 |
|
| 118 |
-
|**Orion-14B-Base**| **64.
|
| 119 |
|
| 120 |
### 3.1.4. Comparison of LLM performances on Japanese testsets
|
| 121 |
| Model |**Average**| JCQA | JNLI | MARC | JSQD | JQK | XLS | XWN | MGSM |
|
|
@@ -176,8 +183,7 @@ Model release and download links are provided in the table below:
|
|
| 176 |
| Llama2-13B-Chat | 3.05 | 3.79 | 5.43 | 4.40 | 6.76 | 6.63 | 6.99 | 5.65 | 4.70 |
|
| 177 |
| InternLM-20B-Chat | 3.39 | 3.92 | 5.96 | 5.50 |**7.18**| 6.19 | 6.49 | 6.22 | 4.96 |
|
| 178 |
| **Orion-14B-Chat** | 4.00 | 4.24 | 6.18 |**6.57**| 7.16 |**7.36**|**7.16**|**6.99**| 5.51 |
|
| 179 |
-
|
| 180 |
-
\* use vllm for inference
|
| 181 |
|
| 182 |
## 3.3. LongChat Model Orion-14B-LongChat Benchmarks
|
| 183 |
### 3.3.1. LongChat evaluation of LongBench
|
|
@@ -333,7 +339,7 @@ Truly Useful Robots", OrionStar empowers more people through AI technology.
|
|
| 333 |
|
| 334 |
**The core strengths of OrionStar lies in possessing end-to-end AI application capabilities,** including big data preprocessing, large model pretraining, fine-tuning, prompt engineering, agent, etc. With comprehensive end-to-end model training capabilities, including systematic data processing workflows and the parallel model training capability of hundreds of GPUs, it has been successfully applied in various industry scenarios such as government affairs, cloud services, international e-commerce, and fast-moving consumer goods.
|
| 335 |
|
| 336 |
-
Companies with demands for deploying large-scale model applications are welcome to contact us
|
| 337 |
**Enquiry Hotline: 400-898-7779**<br>
|
| 338 |
**E-mail: [email protected]**
|
| 339 |
|
|
|
|
| 17 |
|
| 18 |
<div align="center">
|
| 19 |
<h1>
|
| 20 |
+
Orion-14B-Chat-RAG
|
| 21 |
</h1>
|
| 22 |
</div>
|
| 23 |
|
|
|
|
| 57 |
- The fine-tuned models demonstrate strong adaptability, excelling in human-annotated blind tests.
|
| 58 |
- The long-chat version supports extremely long texts, extending up to 200K tokens.
|
| 59 |
- The quantized versions reduce model size by 70%, improve inference speed by 30%, with performance loss less than 1%.
|
| 60 |
+
<table style="border-collapse: collapse; width: 100%;">
|
| 61 |
+
<tr>
|
| 62 |
+
<td style="border: none; padding: 10px; box-sizing: border-box;">
|
| 63 |
+
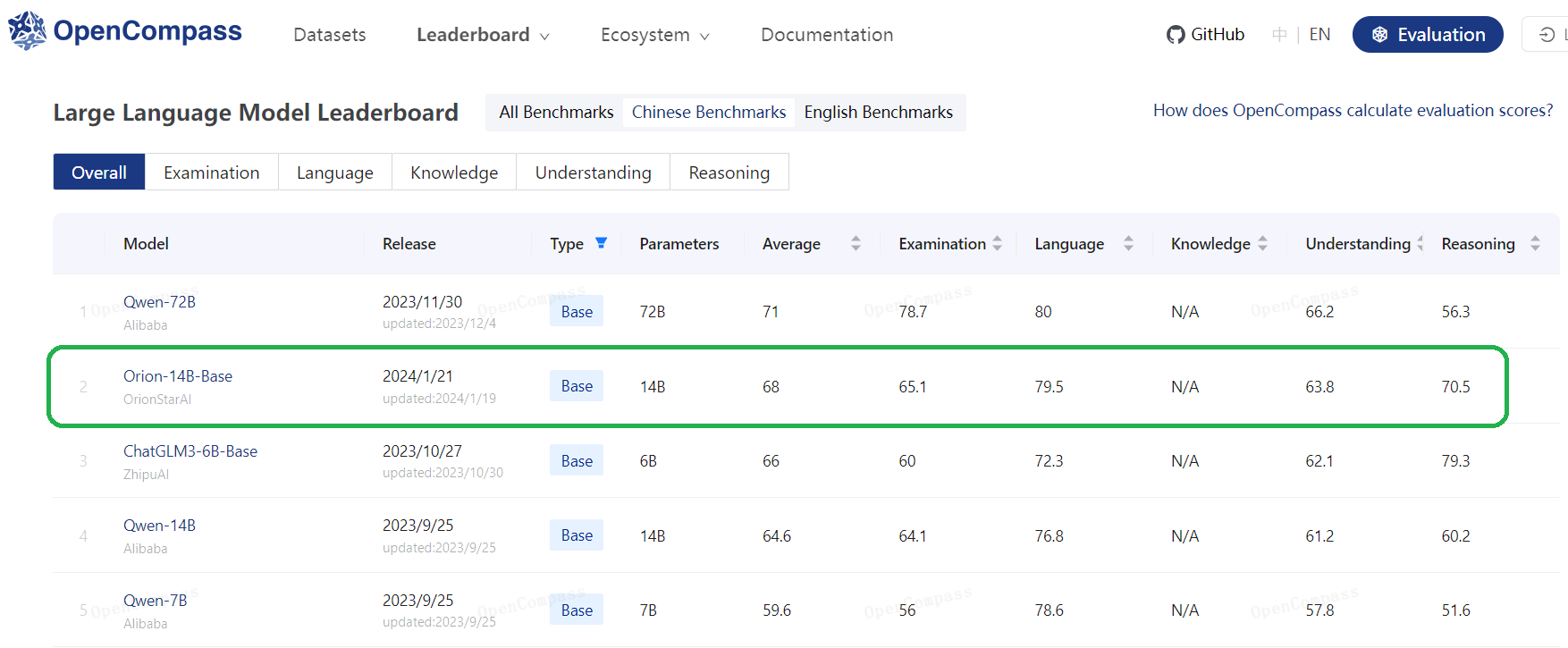
<img src="./assets/imgs/opencompass_en.png" alt="opencompass" style="width: 100%; height: auto;">
|
| 64 |
+
</td>
|
| 65 |
+
<td style="border: none; padding: 10px; box-sizing: border-box;">
|
| 66 |
+
<img src="./assets/imgs/model_cap_en.png" alt="modelcap" style="width: 100%; height: auto;">
|
| 67 |
+
</td>
|
| 68 |
+
</tr>
|
| 69 |
+
</table>
|
| 70 |
|
| 71 |
- Orion-14B series models including:
|
| 72 |
- **Orion-14B-Base:** A multilingual large language foundational model with 14 billion parameters, pretrained on a diverse dataset of 2.5 trillion tokens.
|
|
|
|
| 112 |
| Baichuan 2-13B | 68.9 | 67.2 | 70.8 | 78.1 | 74.1 | 66.3 |
|
| 113 |
| QWEN-14B | 93.0 | 90.3 | **80.2** | 79.8 | 71.4 | 66.3 |
|
| 114 |
| InternLM-20B | 86.4 | 83.3 | 78.1 | **80.3** | 71.8 | 68.3 |
|
| 115 |
+
| **Orion-14B-Base** | **93.2** | **91.3** | 78.5 | 79.5 | **78.8** | **70.2** |
|
| 116 |
|
| 117 |
### 3.1.3. LLM evaluation results of OpenCompass testsets
|
| 118 |
| Model | Average | Examination | Language | Knowledge | Understanding | Reasoning |
|
|
|
|
| 122 |
| Baichuan 2-13B | 49.4 | 51.8 | 47.5 | 48.9 | 58.1 | 44.2 |
|
| 123 |
| QWEN-14B | 62.4 | 71.3 | 52.67 | 56.1 | 68.8 | 60.1 |
|
| 124 |
| InternLM-20B | 59.4 | 62.5 | 55.0 | **60.1** | 67.3 | 54.9 |
|
| 125 |
+
|**Orion-14B-Base**| **64.3** | **71.4** | **55.0** | 60.0 | **71.9** | **61.6** |
|
| 126 |
|
| 127 |
### 3.1.4. Comparison of LLM performances on Japanese testsets
|
| 128 |
| Model |**Average**| JCQA | JNLI | MARC | JSQD | JQK | XLS | XWN | MGSM |
|
|
|
|
| 183 |
| Llama2-13B-Chat | 3.05 | 3.79 | 5.43 | 4.40 | 6.76 | 6.63 | 6.99 | 5.65 | 4.70 |
|
| 184 |
| InternLM-20B-Chat | 3.39 | 3.92 | 5.96 | 5.50 |**7.18**| 6.19 | 6.49 | 6.22 | 4.96 |
|
| 185 |
| **Orion-14B-Chat** | 4.00 | 4.24 | 6.18 |**6.57**| 7.16 |**7.36**|**7.16**|**6.99**| 5.51 |
|
| 186 |
+
\* use vllm for inference
|
|
|
|
| 187 |
|
| 188 |
## 3.3. LongChat Model Orion-14B-LongChat Benchmarks
|
| 189 |
### 3.3.1. LongChat evaluation of LongBench
|
|
|
|
| 339 |
|
| 340 |
**The core strengths of OrionStar lies in possessing end-to-end AI application capabilities,** including big data preprocessing, large model pretraining, fine-tuning, prompt engineering, agent, etc. With comprehensive end-to-end model training capabilities, including systematic data processing workflows and the parallel model training capability of hundreds of GPUs, it has been successfully applied in various industry scenarios such as government affairs, cloud services, international e-commerce, and fast-moving consumer goods.
|
| 341 |
|
| 342 |
+
Companies with demands for deploying large-scale model applications are welcome to contact us.<br>
|
| 343 |
**Enquiry Hotline: 400-898-7779**<br>
|
| 344 |
**E-mail: [email protected]**
|
| 345 |
|
README_cn.md
CHANGED
|
@@ -12,12 +12,12 @@ pipeline_tag: text-generation
|
|
| 12 |
<!-- markdownlint-disable first-line-h1 -->
|
| 13 |
<!-- markdownlint-disable html -->
|
| 14 |
<div align="center">
|
| 15 |
-
<img src="./assets/imgs/orion_start.PNG" alt="logo" width="
|
| 16 |
</div>
|
| 17 |
|
| 18 |
<div align="center">
|
| 19 |
<h1>
|
| 20 |
-
Orion-14B
|
| 21 |
</h1>
|
| 22 |
</div>
|
| 23 |
|
|
@@ -57,18 +57,26 @@ pipeline_tag: text-generation
|
|
| 57 |
- 微调模型适应性强,在人类标注盲测中,表现突出
|
| 58 |
- 长上下文版本支持超长文本,长达200k token
|
| 59 |
- 量化版本模型大小缩小70%,推理速度提升30%,性能损失小于1%
|
| 60 |
-
|
| 61 |
-
|
| 62 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 63 |
|
| 64 |
- 具体而言,Orion-14B系列大语言模型包含:
|
| 65 |
-
- **Orion-14B-Base:** 基于2.5
|
| 66 |
- **Orion-14B-Chat:** 基于高质量语料库微调的对话类模型,旨在为大模型社区提供更好的用户交互体验。
|
| 67 |
-
- **Orion-14B-LongChat:** 支持长度超过200K
|
| 68 |
- **Orion-14B-Chat-RAG:** 在一个定制的检索增强生成数据集上进行微调的聊天模型,在检索增强生成任务中取得了卓越的性能。
|
| 69 |
- **Orion-14B-Chat-Plugin:** 专门针对插件和函数调用任务定制的聊天模型,非常适用于使用代理的相关场景,其中大语言模型充当插件和函数调用系统。
|
| 70 |
-
- **Orion-14B-Base-Int4:** 一个使用
|
| 71 |
-
- **Orion-14B-Chat-Int4:** 一个使用
|
| 72 |
|
| 73 |
# 2. 下载路径
|
| 74 |
|
|
@@ -106,7 +114,7 @@ pipeline_tag: text-generation
|
|
| 106 |
| Baichuan 2-13B | 68.9 | 67.2 | 70.8 | 78.1 | 74.1 | 66.3 |
|
| 107 |
| QWEN-14B | 93.0 | 90.3 | **80.2** | 79.8 | 71.4 | 66.3 |
|
| 108 |
| InternLM-20B | 86.4 | 83.3 | 78.1 | **80.3** | 71.8 | 68.3 |
|
| 109 |
-
| **Orion-14B-Base** | **93.
|
| 110 |
|
| 111 |
### 3.1.3. OpenCompass评测集评估结果
|
| 112 |
| 模型名称 | Average | Examination | Language | Knowledge | Understanding | Reasoning |
|
|
@@ -116,7 +124,7 @@ pipeline_tag: text-generation
|
|
| 116 |
| Baichuan 2-13B | 49.4 | 51.8 | 47.5 | 48.9 | 58.1 | 44.2 |
|
| 117 |
| QWEN-14B | 62.4 | 71.3 | 52.67 | 56.1 | 68.8 | 60.1 |
|
| 118 |
| InternLM-20B | 59.4 | 62.5 | 55.0 | **60.1** | 67.3 | 54.9 |
|
| 119 |
-
|**Orion-14B-Base**| **64.
|
| 120 |
|
| 121 |
### 3.1.4. 日语测试集评估结果
|
| 122 |
| 模型名称 |**Average**| JCQA | JNLI | MARC | JSQD | JQK | XLS | XWN | MGSM |
|
|
@@ -166,6 +174,7 @@ pipeline_tag: text-generation
|
|
| 166 |
| Llama2-13B-Chat | 7.10 | 6.20 | 6.65 |
|
| 167 |
| InternLM-20B-Chat | 7.03 | 5.93 | 6.48 |
|
| 168 |
| **Orion-14B-Chat** | **7.68** | **7.07** | **7.37** |
|
|
|
|
| 169 |
\*这里评测使用vllm进行推理
|
| 170 |
|
| 171 |
### 3.2.2. 对话模型AlignBench主观评估
|
|
@@ -176,6 +185,7 @@ pipeline_tag: text-generation
|
|
| 176 |
| Llama2-13B-Chat | 3.05 | 3.79 | 5.43 | 4.40 | 6.76 | 6.63 | 6.99 | 5.65 | 4.70 |
|
| 177 |
| InternLM-20B-Chat | 3.39 | 3.92 | 5.96 | 5.50 | **7.18** | 6.19 | 6.49 | 6.22 | 4.96 |
|
| 178 |
| **Orion-14B-Chat** | 4.00 | 4.24 | 6.18 | **6.57** | 7.16 | **7.36** | **7.16** | **6.99** | 5.51 |
|
|
|
|
| 179 |
\*这里评测使用vllm进行推理
|
| 180 |
|
| 181 |
## 3.3. 长上下文模型Orion-14B-LongChat评估
|
|
|
|
| 12 |
<!-- markdownlint-disable first-line-h1 -->
|
| 13 |
<!-- markdownlint-disable html -->
|
| 14 |
<div align="center">
|
| 15 |
+
<img src="./assets/imgs/orion_start.PNG" alt="logo" width="30%" />
|
| 16 |
</div>
|
| 17 |
|
| 18 |
<div align="center">
|
| 19 |
<h1>
|
| 20 |
+
Orion-14B-Chat-RAG
|
| 21 |
</h1>
|
| 22 |
</div>
|
| 23 |
|
|
|
|
| 57 |
- 微调模型适应性强,在人类标注盲测中,表现突出
|
| 58 |
- 长上下文版本支持超长文本,长达200k token
|
| 59 |
- 量化版本模型大小缩小70%,推理速度提升30%,性能损失小于1%
|
| 60 |
+
|
| 61 |
+
<table style="border-collapse: collapse; width: 100%;">
|
| 62 |
+
<tr>
|
| 63 |
+
<td style="border: none; padding: 10px; box-sizing: border-box;">
|
| 64 |
+
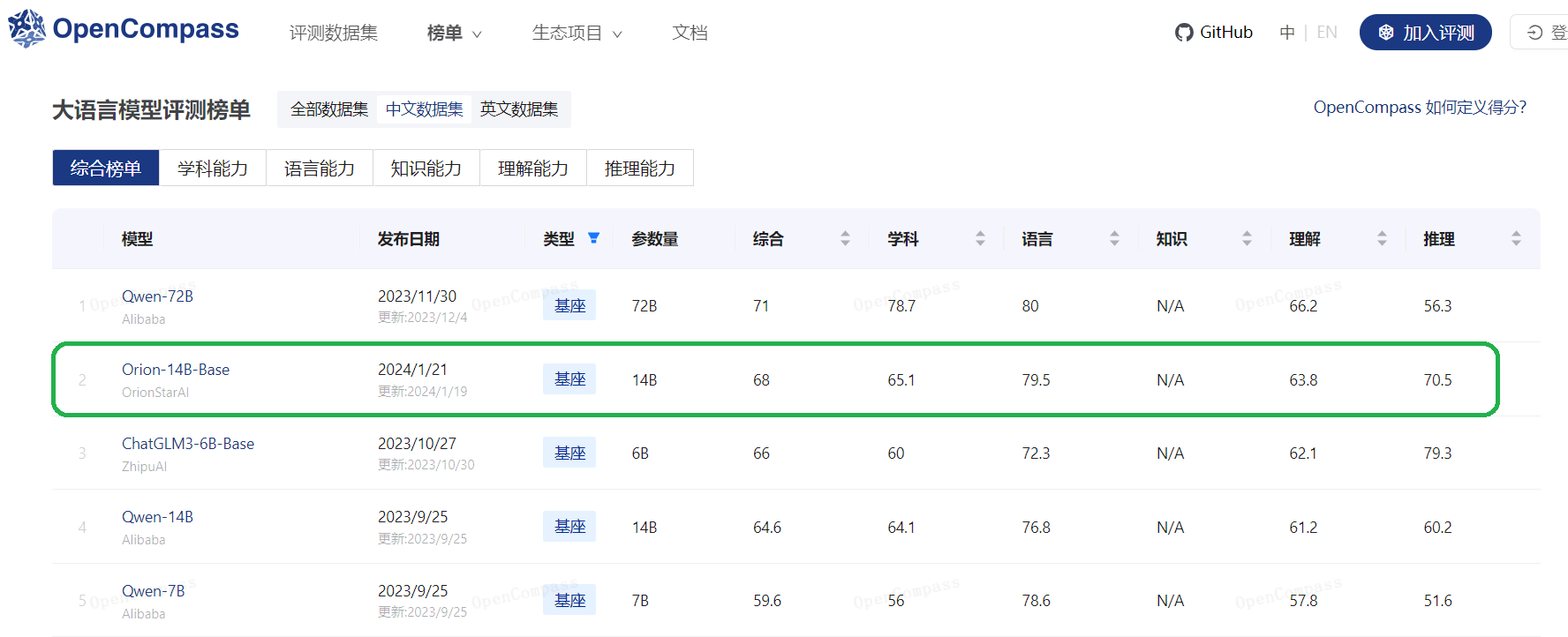
<img src="./assets/imgs/opencompass_zh.png" alt="opencompass" style="width: 100%; height: auto;">
|
| 65 |
+
</td>
|
| 66 |
+
<td style="border: none; padding: 10px; box-sizing: border-box;">
|
| 67 |
+
<img src="./assets/imgs/model_cap_zh.png" alt="modelcap" style="width: 100%; height: auto;">
|
| 68 |
+
</td>
|
| 69 |
+
</tr>
|
| 70 |
+
</table>
|
| 71 |
|
| 72 |
- 具体而言,Orion-14B系列大语言模型包含:
|
| 73 |
+
- **Orion-14B-Base:** 基于2.5万亿tokens多样化数据集训练处的140亿参数量级的多语言基座模型。
|
| 74 |
- **Orion-14B-Chat:** 基于高质量语料库微调的对话类模型,旨在为大模型社区提供更好的用户交互体验。
|
| 75 |
+
- **Orion-14B-LongChat:** 支持长度超过200K tokens上下文的交互,在长文本评估集上性能比肩专有模型。
|
| 76 |
- **Orion-14B-Chat-RAG:** 在一个定制的检索增强生成数据集上进行微调的聊天模型,在检索增强生成任务中取得了卓越的性能。
|
| 77 |
- **Orion-14B-Chat-Plugin:** 专门针对插件和函数调用任务定制的聊天模型,非常适用于使用代理的相关场景,其中大语言模型充当插件和函数调用系统。
|
| 78 |
+
- **Orion-14B-Base-Int4:** 一个使用int4进行量化的基座模型。它将模型大小显著减小了70%,同时提高了推理速度30%,仅引入了1%的最小性能损失。
|
| 79 |
+
- **Orion-14B-Chat-Int4:** 一个使用int4进行量化的对话模型。
|
| 80 |
|
| 81 |
# 2. 下载路径
|
| 82 |
|
|
|
|
| 114 |
| Baichuan 2-13B | 68.9 | 67.2 | 70.8 | 78.1 | 74.1 | 66.3 |
|
| 115 |
| QWEN-14B | 93.0 | 90.3 | **80.2** | 79.8 | 71.4 | 66.3 |
|
| 116 |
| InternLM-20B | 86.4 | 83.3 | 78.1 | **80.3** | 71.8 | 68.3 |
|
| 117 |
+
| **Orion-14B-Base** | **93.2** | **91.3** | 78.5 | 79.5 | **78.8** | **70.2** |
|
| 118 |
|
| 119 |
### 3.1.3. OpenCompass评测集评估结果
|
| 120 |
| 模型名称 | Average | Examination | Language | Knowledge | Understanding | Reasoning |
|
|
|
|
| 124 |
| Baichuan 2-13B | 49.4 | 51.8 | 47.5 | 48.9 | 58.1 | 44.2 |
|
| 125 |
| QWEN-14B | 62.4 | 71.3 | 52.67 | 56.1 | 68.8 | 60.1 |
|
| 126 |
| InternLM-20B | 59.4 | 62.5 | 55.0 | **60.1** | 67.3 | 54.9 |
|
| 127 |
+
|**Orion-14B-Base**| **64.3** | **71.4** | **55.0** | 60.0 | **71.9** | **61.6** |
|
| 128 |
|
| 129 |
### 3.1.4. 日语测试集评估结果
|
| 130 |
| 模型名称 |**Average**| JCQA | JNLI | MARC | JSQD | JQK | XLS | XWN | MGSM |
|
|
|
|
| 174 |
| Llama2-13B-Chat | 7.10 | 6.20 | 6.65 |
|
| 175 |
| InternLM-20B-Chat | 7.03 | 5.93 | 6.48 |
|
| 176 |
| **Orion-14B-Chat** | **7.68** | **7.07** | **7.37** |
|
| 177 |
+
|
| 178 |
\*这里评测使用vllm进行推理
|
| 179 |
|
| 180 |
### 3.2.2. 对话模型AlignBench主观评估
|
|
|
|
| 185 |
| Llama2-13B-Chat | 3.05 | 3.79 | 5.43 | 4.40 | 6.76 | 6.63 | 6.99 | 5.65 | 4.70 |
|
| 186 |
| InternLM-20B-Chat | 3.39 | 3.92 | 5.96 | 5.50 | **7.18** | 6.19 | 6.49 | 6.22 | 4.96 |
|
| 187 |
| **Orion-14B-Chat** | 4.00 | 4.24 | 6.18 | **6.57** | 7.16 | **7.36** | **7.16** | **6.99** | 5.51 |
|
| 188 |
+
|
| 189 |
\*这里评测使用vllm进行推理
|
| 190 |
|
| 191 |
## 3.3. 长上下文模型Orion-14B-LongChat评估
|
assets/imgs/opencompass_en.png
ADDED
|
assets/imgs/opencompass_zh.png
ADDED
|