
upload model
Browse files- README.md +36 -0
- README_zh-CN.md +34 -0
- config.json +28 -0
- generation_config.json +7 -0
- model.safetensors +3 -0
- special_tokens_map.json +23 -0
- static/result.png +0 -0
- tokenizer.json +0 -0
- tokenizer_config.json +37 -0
README.md
CHANGED
|
@@ -1,3 +1,39 @@
|
|
| 1 |
---
|
| 2 |
license: gpl-3.0
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: gpl-3.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
---
|
| 6 |
+
# NanoLM-365M-base
|
| 7 |
+
|
| 8 |
+
English | [简体中文](README_zh-CN.md)
|
| 9 |
+
|
| 10 |
+
## Introduction
|
| 11 |
+
|
| 12 |
+
Based on [Qwen2-0.5B](https://huggingface.co/Qwen/Qwen2-0.5B), the tokenizer has been replaced with [BilingualTokenizer-8K](https://huggingface.co/Mxode/Bilingual-Tokenizer) to reduce the number of parameters. The total parameters have been reduced from 0.5B to 365M.
|
| 13 |
+
|
| 14 |
+
## Details
|
| 15 |
+
|
| 16 |
+
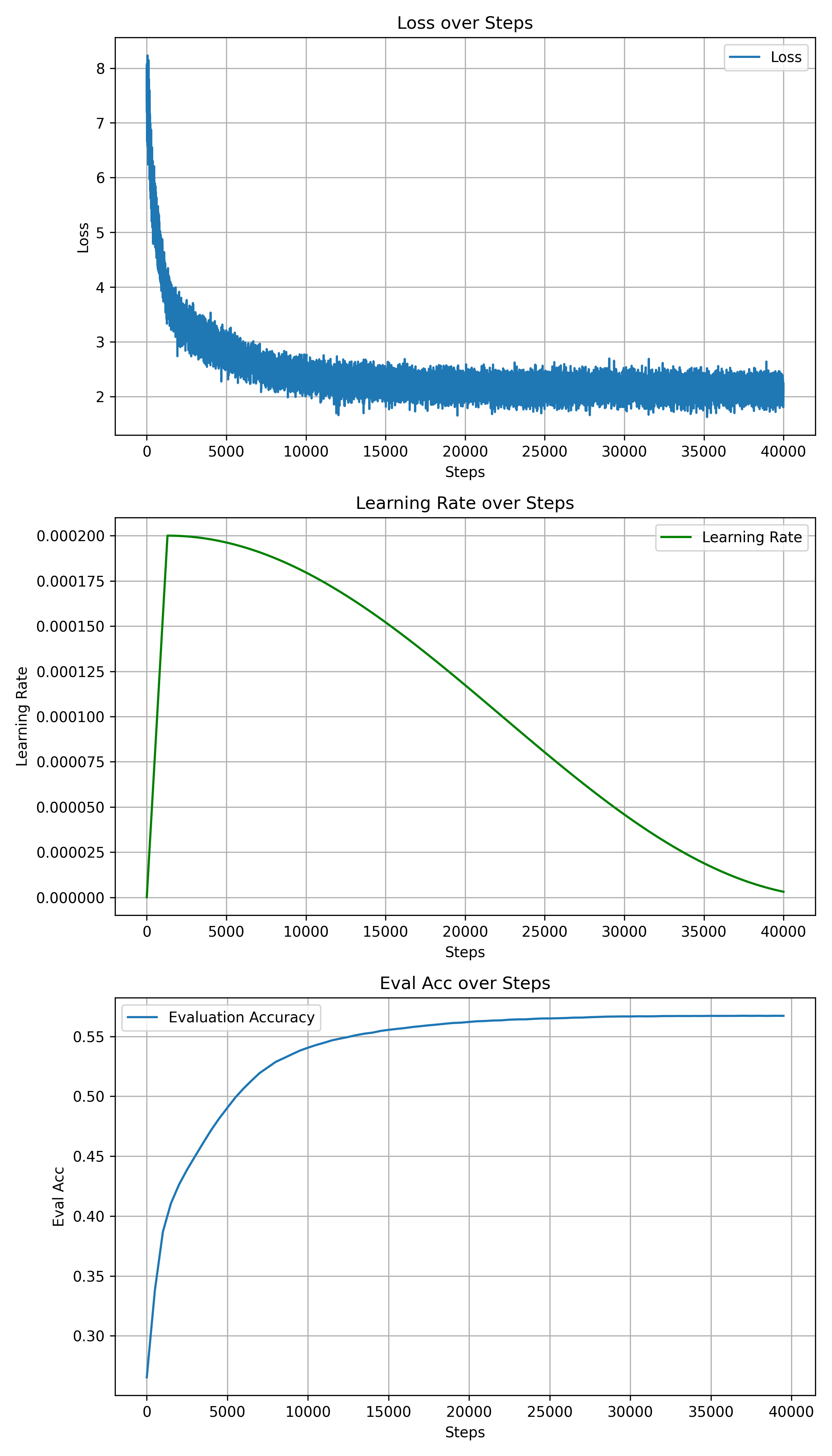
To recover some performance and facilitate fine-tuning for downstream tasks, I chose to freeze the backbone parameters and only train the embedding part after replacing the tokenizer. Training was conducted for 40,000 steps on [wikipedia-zh](https://huggingface.co/datasets/pleisto/wikipedia-cn-20230720-filtered) and [cosmopedia-100k](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia-100k).
|
| 17 |
+
|
| 18 |
+
| | Value |
|
| 19 |
+
| :-------------------------: | :----------------------------------------------------------: |
|
| 20 |
+
| Total Params | 365 M |
|
| 21 |
+
| Trainable Params | < 10 M |
|
| 22 |
+
| Trainable Parts | `model.embed_tokens` |
|
| 23 |
+
| Training Steps | 40,000 |
|
| 24 |
+
| Training Dataset | [wikipedia-zh](https://huggingface.co/datasets/pleisto/wikipedia-cn-20230720-filtered), [cosmopedia-100k](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia-100k) |
|
| 25 |
+
| Optimizer | adamw_torch |
|
| 26 |
+
| Learning Rate | 2e-4 |
|
| 27 |
+
| LR Scheduler | cosine |
|
| 28 |
+
| Weight Decay | 0.1 |
|
| 29 |
+
| Warm-up Ratio | 0.03 |
|
| 30 |
+
| Batch Size | 16 |
|
| 31 |
+
| Gradient Accumulation Steps | 1 |
|
| 32 |
+
| Seq Len | 4096 |
|
| 33 |
+
| Dtype | bf16 |
|
| 34 |
+
| Peak GPU Memory | < 48 GB |
|
| 35 |
+
| Device | NVIDIA A100-SXM4-80GB |
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
The specific training records are as follows:
|
| 39 |
+

|
README_zh-CN.md
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# NanoLM-365M-base
|
| 2 |
+
|
| 3 |
+
English | [简体中文](README_zh-CN.md)
|
| 4 |
+
|
| 5 |
+
## Introduction
|
| 6 |
+
|
| 7 |
+
在 [Qwen2-0.5B](https://huggingface.co/Qwen/Qwen2-0.5B) 的基础上,将 tokenizer 替换为了 [BilingualTokenizer-8K](https://huggingface.co/Mxode/Bilingual-Tokenizer),以达到减小参数的目的。总参数从 0.5B 降低到了 365M。
|
| 8 |
+
|
| 9 |
+
## Details
|
| 10 |
+
|
| 11 |
+
为了恢复一定的性能,便于下游任务微调,替换 tokenizer 后我选择冻结主干参数,仅训练 embedding 部分,在 [wikipedia-zh](https://huggingface.co/datasets/pleisto/wikipedia-cn-20230720-filtered) 和 [cosmopedia-100k](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia-100k) 上训练了 40,000 steps。
|
| 12 |
+
|
| 13 |
+
| | Value |
|
| 14 |
+
| :-------------------------: | :----------------------------------------------------------: |
|
| 15 |
+
| Total Params | 365 M |
|
| 16 |
+
| Trainable Params | < 10 M |
|
| 17 |
+
| Trainable Parts | `model.embed_tokens` |
|
| 18 |
+
| Training Steps | 40,000 |
|
| 19 |
+
| Training Dataset | [wikipedia-zh](https://huggingface.co/datasets/pleisto/wikipedia-cn-20230720-filtered), [cosmopedia-100k](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia-100k) |
|
| 20 |
+
| Optimizer | adamw_torch |
|
| 21 |
+
| Learning Rate | 2e-4 |
|
| 22 |
+
| LR Scheduler | cosine |
|
| 23 |
+
| Weight Decay | 0.1 |
|
| 24 |
+
| Warm-up Ratio | 0.03 |
|
| 25 |
+
| Batch Size | 16 |
|
| 26 |
+
| Gradient Accumulation Steps | 1 |
|
| 27 |
+
| Seq Len | 4096 |
|
| 28 |
+
| Dtype | bf16 |
|
| 29 |
+
| Peak GPU Memory | < 48 GB |
|
| 30 |
+
| Device | NVIDIA A100-SXM4-80GB |
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
具体训练记录如下:
|
| 34 |
+

|
config.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "Mxode/NanoLM-365M-base",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"Qwen2ForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 151643,
|
| 8 |
+
"eos_token_id": 151643,
|
| 9 |
+
"hidden_act": "silu",
|
| 10 |
+
"hidden_size": 896,
|
| 11 |
+
"initializer_range": 0.02,
|
| 12 |
+
"intermediate_size": 4864,
|
| 13 |
+
"max_position_embeddings": 131072,
|
| 14 |
+
"max_window_layers": 24,
|
| 15 |
+
"model_type": "qwen2",
|
| 16 |
+
"num_attention_heads": 14,
|
| 17 |
+
"num_hidden_layers": 24,
|
| 18 |
+
"num_key_value_heads": 2,
|
| 19 |
+
"rms_norm_eps": 1e-06,
|
| 20 |
+
"rope_theta": 1000000.0,
|
| 21 |
+
"sliding_window": 131072,
|
| 22 |
+
"tie_word_embeddings": true,
|
| 23 |
+
"torch_dtype": "bfloat16",
|
| 24 |
+
"transformers_version": "4.42.0",
|
| 25 |
+
"use_cache": false,
|
| 26 |
+
"use_sliding_window": false,
|
| 27 |
+
"vocab_size": 8000
|
| 28 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 151643,
|
| 3 |
+
"eos_token_id": 2,
|
| 4 |
+
"max_new_tokens": 2048,
|
| 5 |
+
"pad_token_id": 0,
|
| 6 |
+
"transformers_version": "4.42.0"
|
| 7 |
+
}
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:12f1d14eb87b662615915bfc3aaa203e5013fe9b184bbabdc41590232e62556b
|
| 3 |
+
size 730164456
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|endoftext|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|im_end|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "<|endoftext|>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
}
|
| 23 |
+
}
|
static/result.png
ADDED
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "<|endoftext|>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"1": {
|
| 12 |
+
"content": "<|im_start|>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"2": {
|
| 20 |
+
"content": "<|im_end|>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
}
|
| 27 |
+
},
|
| 28 |
+
"bos_token": "<|endoftext|>",
|
| 29 |
+
"chat_template": "{% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n' }}{% endif %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
| 30 |
+
"clean_up_tokenization_spaces": false,
|
| 31 |
+
"eos_token": "<|im_end|>",
|
| 32 |
+
"errors": "replace",
|
| 33 |
+
"model_max_length": 4096,
|
| 34 |
+
"pad_token": "<|endoftext|>",
|
| 35 |
+
"split_special_tokens": false,
|
| 36 |
+
"tokenizer_class": "PreTrainedTokenizerFast"
|
| 37 |
+
}
|