
File size: 2,494 Bytes
e2a0278 38a9131 e2a0278 ed71434 e2a0278 6e7490e |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
---
license: mit
pipeline_tag: image-text-to-text
tags:
- text-generation-inference
---
<h2 align="center"> <a href="https://arxiv.org/abs/2405.14297">Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models</a></h2>
<h5 align="center"> If our project helps you, please give us a star ⭐ on <a href="https://github.com/LINs-lab/DynMoE">GitHub</a> and cite our paper!</h2>
<h5 align="center">
## 📰 News
- **[2024.05.31]** 🔥 Our [code](https://github.com/LINs-lab/DynMoE/) is released!
- **[2024.05.25]** 🔥 Our **checkpoints** are available now!
- **[2024.05.23]** 🔥 Our [paper](https://arxiv.org/abs/2405.14297) is released!
## 😎 What's Interesting?
**Dynamic Mixture of Experts (DynMoE)** incorporates (1) a novel gating method that enables each token to automatically determine the number of experts to activate. (2) An adaptive process automatically adjusts the number of experts during training.
### Top-Any Gating
<video controls src="https://i.imgur.com/bLgNaoH.mp4" title="Top-Any Gating"></video>
### Adaptive Training Process
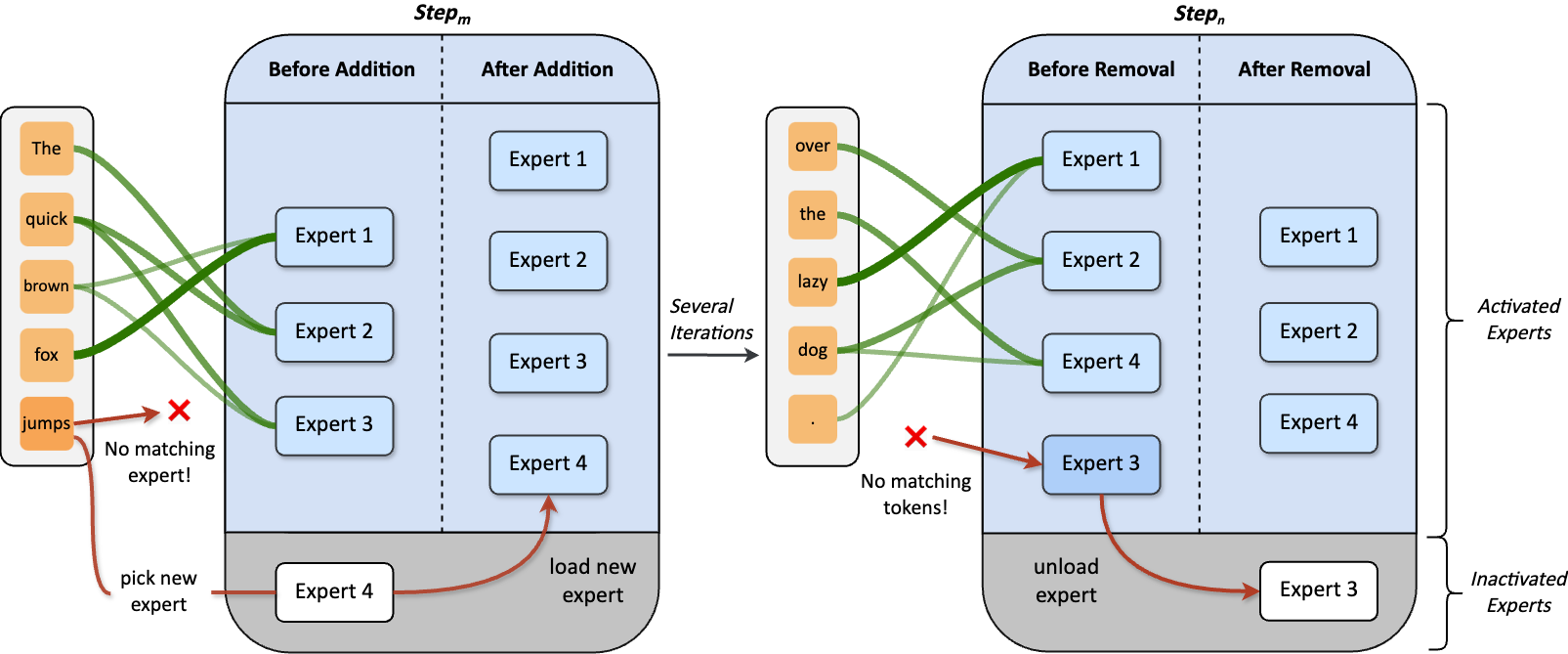
## 💡 Model Details
- 🤔 DynMoE-StableLM is a MoE model with **dynamic top-k gating**, finetuned on [LanguageBind/MoE-LLaVA-StableLM-Stage2](https://huggingface.co/LanguageBind/MoE-LLaVA-StableLM-Stage2).
- 🚀 Our DynMoE-StableLM-1.6B has totally 2.9B parameters, but **only 1.8B are activated!** (average top-k = 1.25)
- ⌛ With the DynMoE tuning stage, we can complete training on 8 A100 GPUs **within 40 hours.**
## 👍 Acknowledgement
We are grateful for the following awesome projects:
- [tutel](https://github.com/microsoft/tutel)
- [DeepSpeed](https://github.com/microsoft/DeepSpeed)
- [GMoE](https://github.com/Luodian/Generalizable-Mixture-of-Experts)
- [EMoE](https://github.com/qiuzh20/EMoE)
- [MoE-LLaVA](https://github.com/PKU-YuanGroup/MoE-LLaVA)
- [GLUE-X](https://github.com/YangLinyi/GLUE-X)
## 🔒 License
This project is released under the MIT license as found in the [LICENSE](https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/mit.md) file.
## ✏️ Citation
```tex
@misc{guo2024dynamic,
title={Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models},
author={Yongxin Guo and Zhenglin Cheng and Xiaoying Tang and Tao Lin},
year={2024},
eprint={2405.14297},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
``` |