[//]: # (
)
モデルリポジトリ:[modelscope](https://www.modelscope.cn/models/iic/SenseVoiceSmall),[huggingface](https://huggingface.co/FunAudioLLM/SenseVoiceSmall)
オンライン体験:
[modelscope demo](https://www.modelscope.cn/studios/iic/SenseVoice), [huggingface space](https://huggingface.co/spaces/FunAudioLLM/SenseVoice)



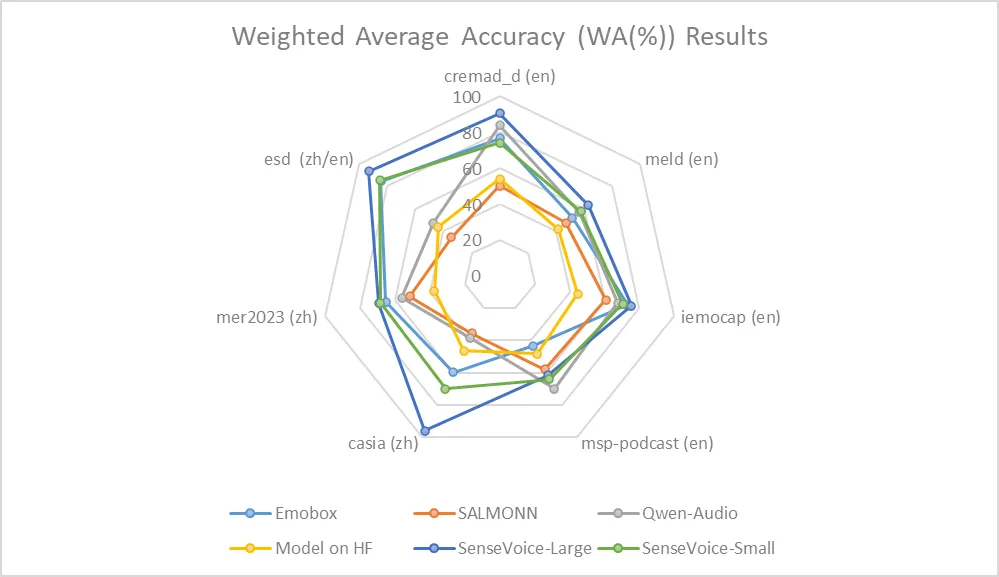



 |
|